
티스토리 뷰
따로 운영중인 반복적인 네이버 블로그 발행 작업을 줄이기 위해 자동화 프로젝트를 시작했다.
처음에는 글 생성 자동화에 집중했지만, 실제로는 네이버 에디터에 내용을 넣고 발행 준비를 마치는 마지막 단계가 가장 큰 병목이었다.
이 글은 그 병목을 해결하기 위해 왜 크롬 익스텐션을 선택했는지, 어떤 기술 스택으로 구현했는지, 어디서 어려움을 겪고 있는지까지 전체 과정을 정리한 기록이다.
프로젝트를 시작한 배경
블로그 운영 과정에서 주제 정리, 자료 조사, 본문 작성, 이미지 구성, 네이버 업로드, 발행 설정까지 반복되는 수작업이 많았다.
러프한 스케치만 된 상태인데, 쉽게 말하면 아래와 같은 서비스다. (아직 구현중)
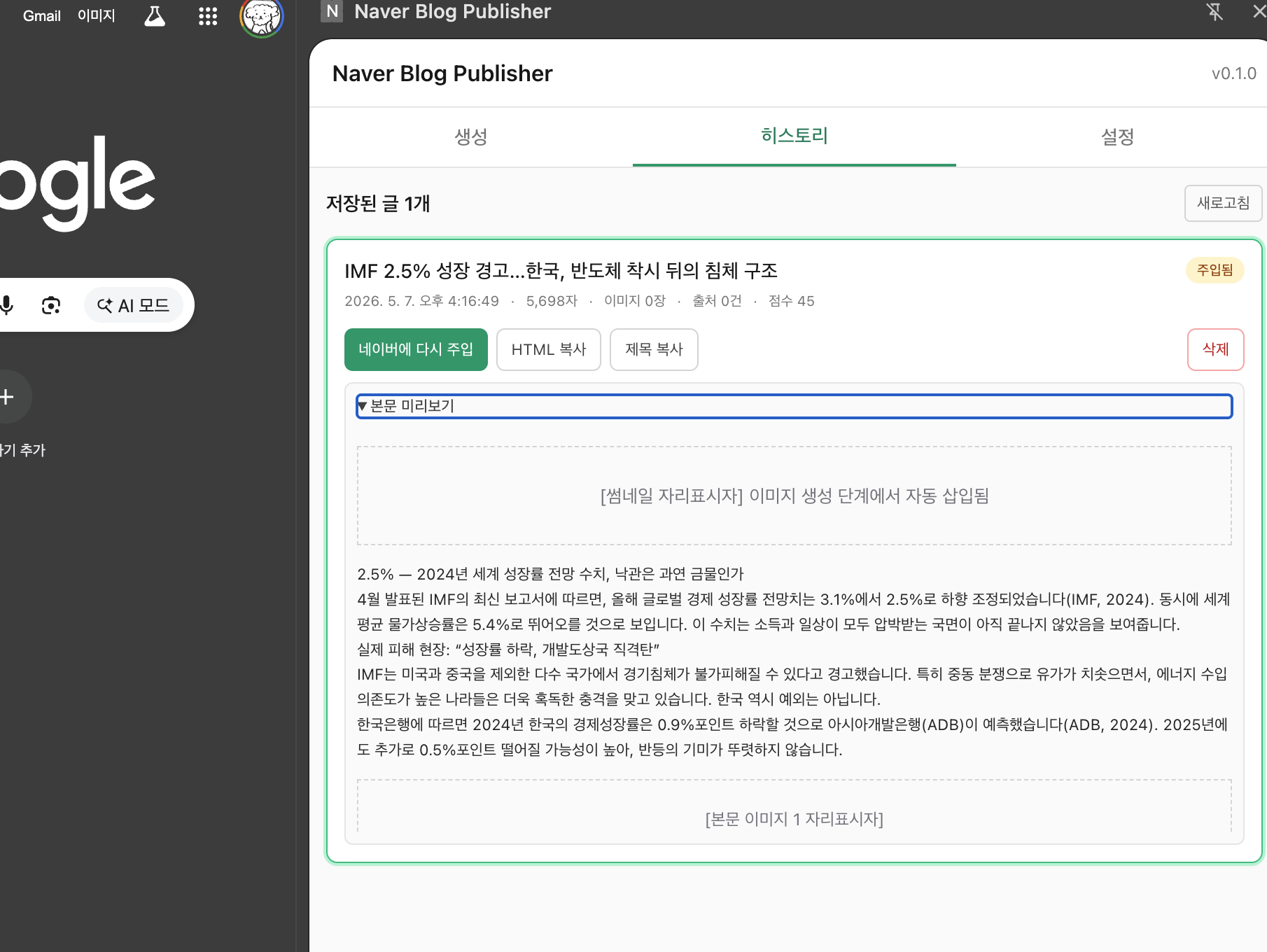
왜 크롬 익스텐션을 선택했는가
네이버 블로그는 공식 글쓰기 API가 없고, 티스토리처럼 단순한 HTML 모드를 제공하지 않는다.
결국 사용자가 로그인한 실제 브라우저 컨텍스트에서 편집기 DOM과 입력 이벤트를 직접 다루는 방식이 필요했다.
이 조건을 만족하는 현실적인 방법이 크롬 익스텐션이었다.

기술 스택 선정 이유
처음 익스텐션을 만드는 입장에서, 개발 속도와 안정성을 동시에 확보할 수 있는 조합이 필요했다.
Vite는 빠른 빌드와 개발 경험 측면에서 유리했고, TypeScript는 메시지 기반 아키텍처에서 타입 안정성을 확보하는 데 필수였다.
사이드패널 UI는 상태 기반으로 동작해야 해서 React 기반으로 구성했다.
Vite를 사용한 이유
익스텐션은 엔트리 포인트가 여러 개다.
백그라운드 서비스 워커, 콘텐츠 스크립트, 사이드패널이 각각 다른 실행 컨텍스트를 가진다.
Vite는 이 구조를 빠르게 번들링하고 개발 반복 속도를 높이는 데 적합했다.
초기 시행착오를 줄이는 데 큰 도움이 됐다.
TypeScript를 사용한 이유
익스텐션에서는 메시지 타입이 곧 계약이다.
한쪽에서 보내는 메시지와 다른 쪽에서 기대하는 payload가 조금만 달라도 런타임 오류가 발생한다.
TypeScript로 ExtensionMessage, ExtensionResponse 같은 구조를 고정해두면, 리팩터링 시 안정성이 크게 올라간다.
Manifest V3 구조에서 고려한 점
MV3의 백그라운드는 서비스 워커로 동작한다.
상시 실행 프로세스가 아니라 이벤트 기반으로 깨고 잠드는 구조라서, 처리 흐름을 메시지 단위로 분리하고 상태를 저장소 중심으로 다루는 설계가 필요했다.
권한도 기능 기준으로 최소화하면서 scripting, tabs, storage, sidePanel 등을 명시했다.
아키텍처 구성 방식
구조는 세 층으로 분리했다.
- 사이드패널: 생성 결과 확인, 복사, 자동 주입 트리거
- 서비스 워커: 메시지 라우팅, 탭 탐색, 자동화 오케스트레이션
- 주입 모듈: 네이버 편집기 DOM 탐색, 제목/본문 입력, 발행 레이어 조작
이렇게 분리하면 실패 지점을 빨리 찾을 수 있다.
네이버 글쓰기 페이지 판별 방식
네이버 글쓰기 URL이 단일하지 않아서 패턴 기반 판별 로직이 필요했다.
PostWriteForm, GoBlogWrite, Redirect=Write 등 여러 경로를 체크해 실제 글쓰기 탭만 자동화 대상으로 잡도록 했다.
콘텐츠 스크립트와 메인 월드 처리 방식
편집기 종류에 따라 content script에서 단순 DOM 조작만으로는 반영되지 않는 경우가 있다.
그래서 chrome.scripting.executeScript를 통해 메인 월드에서 실행하는 전략을 사용했다.
또한 프레임 구조를 고려해 allFrames 실행 후 실제 편집기 프레임인지 추가 필터링했다.
본문 주입 로직의 핵심 전략
단일 방식으로는 성공률이 낮아서 다중 fallback 전략을 적용했다.
- insertHTML
- paste 이벤트 디스패치
- insertText
- InputEvent 기반 입력
- 최종 fallback으로 innerHTML
그리고 각 단계마다 실제 반영 여부를 검증했다.
“시도 성공”이 아니라 “에디터 상태 반영 성공”을 기준으로 결과를 판정했다.
발행 레이어 자동화 방식
본문 주입 성공 후 발행 버튼을 찾아 클릭하고, 카테고리/예약 발행 설정까지 자동으로 시도했다.
카테고리는 텍스트 매칭 기반, 예약은 날짜/시간 input 탐색 후 네이티브 value setter와 이벤트 트리거 방식으로 처리했다.
이 부분은 DOM 변경 가능성이 높아 상세 결과 메시지를 함께 반환하도록 만들었다.
OpenAI 연동을 넣은 이유와 방식
생성 품질과 생산성을 동시에 확보하기 위해 OpenAI API 기반 생성 파이프라인을 구성했다.
제목, 본문, 태그 생성 흐름을 자동화하고, 진행 상태를 단계별로 UI에 보여주도록 설계했다.
오류가 발생하면 즉시 사용자에게 원인을 전달해 재시도 가능성을 높였다.
OpenAI 는 일단 10달러만 미리 충전해놓고, API Key를 발급해서 테스트 해보는 중이다.
혹시나해서 API 비용 리미트도 걸어두었다.
테스트 하느라고 벌써 62,328 토큰이나 소모했다.

Cloudflare R2 연동을 넣은 이유와 방식
이미지 자산을 안정적으로 관리하고 직접 첨부하여 넣는 공수를 줄이기 위해 Cloudflare R2를 연동했다.
생성된 이미지 URL을 본문 HTML과 미리보기에서 재사용하고, 사이드패널 CSP를 조정해 외부 이미지 미리보기가 동작하도록 구성했다.
이 덕분에 생성 결과물의 자산 경로를 일관되게 유지할 수 있었다.
가장 어려웠던 점
가장 어려운 지점은 네이버 편집기 HTML 주입 안정화였다.
네이버는 글쓰기 API가 없고 HTML 모드가 명확하지 않아서, DOM 직접 주입이 사실상 유일한 방법이었다.
문제는 단순 삽입이 아니라 편집기가 기대하는 이벤트 흐름과 내부 상태를 맞추는 것이었다.
현재는 성공률을 높였지만, 완전한 안정화는 아직 진행 중이다.
현재 상태와 다음 계획
현재는 생성-검토-자동주입-발행준비까지 기본 파이프라인이 연결된 상태다.
다음 단계는 DOM 변경 내성을 높이고, 실패 진단 로그를 강화하고, 입력 반영 검증을 더 정밀하게 만드는 것이다.
목표는 완전 자동화보다 “반자동 + 빠른 복구” 경험을 더 견고하게 만드는 데 있다.
그리고 지금 OpenAI로 글감 생성이 되는데 이미지 생성은 계속 fail이 나타나고 OpenAI 대시보드에서도 토큰 소비가 안되는 중이다.
원인을 찾아봐야한다.
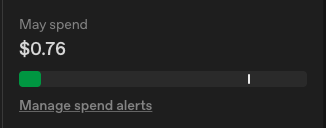
아래 처럼 Images 생성도 함께 보내고 있는데, 이미지 생성부터 실패인건지 Cloudflare R2에 올리고 URL만 가져오는게 안되는 것인지 확인해볼 필요가 있다.

그나저나 테스트 한 4번 정도 해봤는데 벌써 0.76 달러나 썻다.
이래서 프롬프트 엔지니어링이 필요한 것 같다. 그리고 적정 모델을 찾는 것도 중요하단 생각이 들었다.
AI를 이용해서 서비스를 만드는 것은 좋다.
그렇지만 AI를 이용해서 새로운 부가가치를 창출하지 않으면 결국 OpenAI 만 신난 일을 해줄뿐...
이 비싼 API를 이용해서 돈을 더 벌만큼 가치가 높은 서비스여야 한다.
생각보다 AI 사용 비용은 만만치 않다. 그냥 제미나이나 챗지피티, 클로드 유저로써 월 구독으로 사용하는 것과 API 사용할 때의 비용은 정말 크게 다르다는걸 체감한다.

'[WEB]' 카테고리의 다른 글
| Prisma란? 기존 MySQL과의 차이, 마이그레이션까지 정리 (0) | 2026.03.10 |
|---|---|
| Jira 데이터 마이그레이션 경험 정리 (Node + Prisma 기반 실전 회고) (0) | 2026.02.26 |
| Prisma의 네이티브 Query Engine 구조가 Alpine 환경에서 야기한 런타임 멈춤 이슈 정리 (0) | 2026.02.25 |
| Next.js 프로젝트에서 Docker·Prisma·DB가 어떻게 연결되는지 (0) | 2026.02.11 |
| Next.js 프로젝트 AWS 배포 시 고민한 것들 – App Runner, ECS, Lambda, EKS (0) | 2026.02.11 |
- Total
- Today
- Yesterday